Getting started¶
Install¶
tamga requires Python 3.11+.
Optional extras¶
uv pip install "tamga[bayesian]" # PyMC + arviz for hierarchical models
uv pip install "tamga[embeddings]" # sentence-transformers + contextual BERT
uv pip install "tamga[viz]" # plotly, kaleido, ete3
uv pip install "tamga[reports]" # weasyprint for PDF report export
uv pip install "tamga[docs]" # mkdocs + material theme (build this site)
A study in five commands¶
tamga init my-study # (1) scaffold a project directory
cd my-study
# (2) drop .txt files into corpus/
# (3) fill in corpus/metadata.tsv — one row per file with filename → author, group, year, ...
tamga ingest corpus/ --metadata corpus/metadata.tsv # (4) parse + cache
tamga info # (5a) verify the ingest
tamga run study.yaml --name demo # (5b) run the declared study
tamga report results/demo --output results/demo/report.html
The project skeleton from tamga init includes a working study.yaml with Burrows Delta
+ PCA + Zeta on 200 most-frequent words, so the above sequence runs end-to-end on any
corpus you ingest.
Your first Python session¶
from tamga import (
Corpus, Document,
MFWExtractor, BurrowsDelta,
PCAReducer, plot_scatter_2d,
)
corpus = Corpus(documents=[
Document(id="d1", text=open("doc1.txt").read(), metadata={"author": "Alice"}),
Document(id="d2", text=open("doc2.txt").read(), metadata={"author": "Alice"}),
Document(id="d3", text=open("doc3.txt").read(), metadata={"author": "Bob"}),
Document(id="d4", text=open("doc4.txt").read(), metadata={"author": "Bob"}),
Document(id="q", text=open("questioned.txt").read(), metadata={"author": "?"}),
])
# 1. Extract the most-frequent-word feature matrix.
fm = MFWExtractor(n=200, scale="zscore", lowercase=True).fit_transform(corpus)
# 2. Train Burrows Delta on the known docs and predict the questioned one.
import numpy as np
y = np.array(corpus.metadata_column("author"))
train_mask = y != "?"
clf = BurrowsDelta().fit_predict(fm) # sklearn-compatible
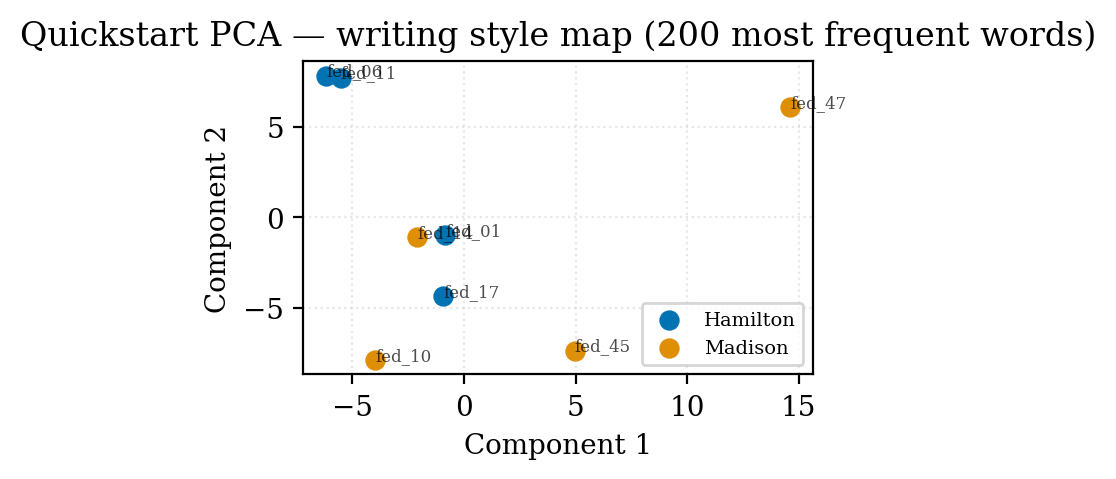
Sample data: the Federalist showcase¶
Two ready-to-run examples ship with the repo:
examples/quickstart/— a beginner-friendly walkthrough using 9 papers including the disputed No. 50.examples/federalist/— the full 85-paper analysis reproducing the Mosteller & Wallace (1964) result.
The quickstart produces this PCA plot on first run:
Next¶
- Learn the shared mental model in Concepts.
- Jump into the Forensic toolkit for verification, LR output, and PAN-style evaluation.
- Reproduce Mosteller & Wallace in the Federalist tutorial.