Türkçe stilometri öğreticisi¶
Küçük bir Türkçe kısa hikaye derleminde MFW + Ateşman okunabilirlik + Burrows Delta kullanarak yazar tespiti yapan, baştan sona çalıştırılabilir bir örnek. Hikayeler, Türkçe Wikisource'dan alınan, telif hakkı süresi dolmuş Ömer Seyfettin metinleridir.
Kurulum¶
uv pip install 'bitig[turkish]'
python -c "import stanza; stanza.download('tr')"
bitig init seyfettin --language tr
cd seyfettin
Bu komut, Türkçe için önceden yapılandırılmış study.yaml içeren bir proje dizini oluşturur.
Şununla doğrulayın:
language satırı tr gösterir.
Derlem¶
corpus/ dizinine UTF-8 .txt dosyası olarak 3-5 Türkçe kısa hikaye ekleyin. İyi bir
telif hakkı süresi dolmuş kaynak, Türkçe Vikiskaynak'taki Ömer Seyfettin
sayfasıdır — 20. yüzyıl başına ait düzinelerce kısa hikaye orada zaten yazıya geçirilmiş durumdadır.
corpus/metadata.tsv dosyasını ekleyin:
filename author year
bomba.txt Omer_Seyfettin 1910
kesik_biyik.txt Omer_Seyfettin 1911
forsa.txt Omer_Seyfettin 1913
pembe_incili_kaftan.txt Omer_Seyfettin 1917
Gerçek bir çalışmada birden fazla yazar olması gerekir. Tek yazarlı demo için Seyfettin'i birkaç Refik Halit Karay hikayesiyle eşleştirin (o da telif hakkı süresi dolmuş) — böylece Delta'nın ayırt edecek bir şeyi olur.
Çalışmayı çalıştırın¶
bitig ingest corpus/ --language tr --metadata corpus/metadata.tsv
bitig run study.yaml --name first-run
bitig ingest, Stanza'yı spacy-stanza aracılığıyla çalıştırır. İlk çalıştırma her belgeyi
ayrıştırır ve DocBin'leri önbelleğe alır; sonraki çalıştırmalar önbellekten okur ve saniyeler
içinde tamamlanır.
Çıktılar¶
Varsayılan bir Türkçe çalışma şunları hesaplar:
- MFW (ilk 1000 belirteç, z-skorlanmış göreli sıklıklar)
- Türkçe işlev sözcükleri — UD Turkish BOUN kapalı sınıf belirteçlerinden türetilen
resources/languages/tr/function_words.txtdosyasından yüklenir - Ateşman ve Bezirci-Yılmaz okunabilirlik endeksleri
- Burrows Delta + PCA/MDS indirgeme grafikleri
results/first-run/ çıktı klasörü şunları içerir:
- Delta skorları ve köken bilgisi içeren
result.json table_*.parquetöznitelik matrisleri- PNG / PDF şekiller (mesafe ısı haritası, PCA dağılım grafiği)
- Derlem özetini, seed değerini ve tam çözümlenmiş yapılandırmayı kaydeden
provenance.json
Çalışan örnek: Ömer Seyfettin'in 28 kısa hikayesi¶
Depodaki examples/turkish_seyfettin/ dizini, Ömer Seyfettin'in
(1884-1920; Türkiye'de telif hakkı süresi 1991'de dolmuştur)
tr.wikisource.org üzerinden fetch_corpus.py
betiği ile çekilip çalışmayla birlikte depoya işlenmiş 28 kısa hikayesi
üzerinde uçtan uca, yeniden üretilebilir bir çalıştırma sunar.
python examples/turkish_seyfettin/fetch_corpus.py --n 30 # ~30s; Wikisource'a saygılı
python -m bitig run examples/turkish_seyfettin/study.yaml --name seyfettin
Derlem. 200 belirteçlik alt sınırı geçen 28 hikaye var; uzunluklar 326 ile
4 455 belirteç arasında (medyan ≈ 1 700). Wikisource transkripsiyonları CC BY-SA 4.0
lisanslıdır; atıf bilgileri ve kaynak URL'ler
examples/turkish_seyfettin/manifest.json dosyasındadır.
Çalışma. En sık 500 sözcük (z-skorlu, min_df = 2) + Türkçe işlev sözcükleri
sıklıkları → Burrows Delta öz-atfetme + PCA + Ward hiyerarşik kümeleme.
Tek-yazar kurguları yazar arası doğrulamayı (Imposters / classify) kabul etmediği
için bu yazar içi keşifsel stilometridir, yazar tespiti değildir.
Burrows Delta öz-atfetme¶
28 hikayelik leave-one-out ızgarasında her hikayenin en yakın komşusu kendisidir
(doğruluk = 1.0). Tek-yazar derlem için bu önemsiz sonuç — her belge kendi MFW
profiline başkasınınkinden daha yakındır — aynı zamanda hiçbir hikayenin yanlış
yazar metaverisiyle etiketlenmediğini doğrular. Esas sinyal bir sıra
sonradadır: 2. en yakın komşular, biçemce yakın hikayeleri yüzeye çıkarır.
Sıralamada kullanılan ikili mesafe matrisi
results/seyfettin/burrows/result.json içinde saklanır.
MFW-500 sözcüksel uzayı üzerinde PCA¶
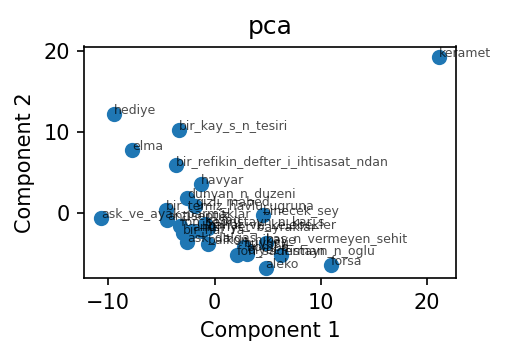
PC1 varyansın % 7.7'sini, PC2 ise % 7.2'sini açıklar. Tek bir bileşenin baskın olmaması başlı başına tanılayıcıdır: tek bir yazarın iç sözcüksel varyansı, bir-iki eksende toplanmak yerine pek çok küçük eksene yayılır. Yazar arası bir PCA ile karşılaştırın (örn. Federalist öğreticisi): orada PC1 tek başına çoğunlukla % 30 ve üzerini yakalar.
En etkili yüklemeler — PC1: baktı, değildi, açtı, durdu, hafif, iki, şeyler, gelince.
PC1, basit-geçmiş 3. tekil anlatım eylemlerine (baktı, açtı, durdu)
yaslanan hikayeleri bunlara yaslanmayanlardan ayırır.
En etkili yüklemeler — PC2: idi, ediyordu, onu, o, olduğu, nihayet, etti, durdu.
PC2, geçmiş-süreğen yardımcısını (idi, ediyordu) ve 3. tekil zamir öbeğini
(onu, o, olduğu) yakalar — yani uzun-durum betimi ile olay-odaklı anlatım
arasındaki seçim.
Biplot, en etkili 12 yükleme vektörünü aynı 2-B izdüşüm üzerine bindirir:
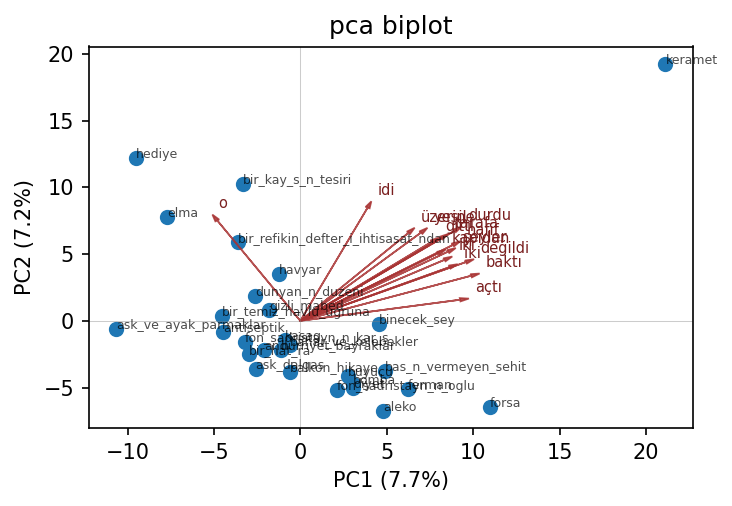
Etkileşimli plotly biplot'ı aç ↗ — hikaye kimliklerini ve ok ucu etiketlerini görmek için imleci üstüne getirin.
Ward hiyerarşik kümeleme (k = 4)¶

Dört düz kümede kesim şunu verir:
| Küme | n | Üye hikaye kimlikleri |
|---|---|---|
| 0 | 23 | derlemin gövdesi (aleko, bomba, kasag, forsa, …) |
| 1 | 3 | bir_refikin_defter_i_ihtisasat_ndan, elma, hediye |
| 2 | 1 | bir_kay_s_n_tesiri |
| 3 | 1 | keramet |
Üç parçalık küme, derlemdeki en kısa üç parçaya karşılık çıkar (329 / 517 / 457 belirteç). İki tekil de kısadır (554 ve 511 belirteç). Dendrogram özünde uzunluk-güdümlü bir sinyal yüzeye çıkarmaktadır: ~600 belirteç altındaki metinlerde z-skorlu MFW sayımları gürültülenir, dolayısıyla kısa hikayeler konudan bağımsız olarak ana buluttan uzaklaşır. Bu yöntem hatası değil — küçük N için MFW kestirim varyansının doğal sonucu — ve bu çözümlemenin verdiği en kullanışlı bilgi de tam olarak budur:
Etkileşimli plotly dendrogramını aç ↗
Türkçe kısa düzyazıda stilometri yapıyorsanız, alt küme yapısından tema/dönem sonuçları çıkarmadan önce belge başına belirteç tabanını en az 1 000'e yükseltin — ya da uzunluğa karşı çok daha hoşgörülü olan karakter n-gramlarına geçin.
Bunun yapmadığı — sınırlamalar¶
Gerçek bir yazar tespiti gösterimi, Wikisource'taki erken-cumhuriyet döneminde benzer kapsama sahip en az bir başka telif hakkı süresi dolmuş Türkçe düzyazı yazarına ihtiyaç duyar; Wikisource:tr şu anda bunu sunmuyor (Refik Halit Karay'ın transkripsiyonları orada bulunsa da altta yatan metinler ancak 2036'da Türkiye'de kamuya geçecektir). Atfetme çalışmaları için Seyfettin'i çağdaş bir edebî yazar yerine farklı bir tür/kayıt dengelemesi sağlayan bir denetim derlemi (örn. meclis konuşmaları, konuya göre Türkçe Wikipedia seçilmiş makaleleri ya da kendi kurumsal derleminiz) ile eşleştirmenizi öneririz.
Özelleştirme¶
Öznitelikleri veya yöntemleri değiştirmek için study.yaml dosyasını düzenleyin. Örneğin,
MFW yerine bağlamsal gömme kullanmak için:
features:
- id: bert_tr
type: contextual_embedding
# model auto-resolves to `dbmdz/bert-base-turkish-cased` via the language registry
pool: mean
Daha ağır bir Türkçe kodlayıcı için model: öğesini herhangi bir HuggingFace denetim
noktasına yönlendirin:
Türkçe'ye özgü notlar¶
- Morfoloji. Türkçe eklemeli bir dildir;
evlerinizdengibi bir belirteçev+ler+iniz+denbiçimlerini tek formda bir araya getirir. Stanza'nın BOUN modeli bu biçimleri doğru şekilde lemmatize eder ve etiketler; bu durum POS n-gram ve bağımlılık tabanlı öznitelikler için önemlidir. Stilometrik çözümleme açısından bu morfolojik zenginlik, sözcük düzeyi MFW listelerini doğrudan Türkçe'ye uygulamak yerine lemma tabanlı ya da kök tabanlı öznitelikleri tercih etmeyi gerektirebilir. - Hece sayımı. Hem Ateşman hem de Bezirci-Yılmaz, Türkçe yazıma özel bir sesli harf sayacı
kullanır (
ı,ğ,ş,ç,ü,ödahil). - İşlev sözcükleri. Paketlenmiş liste, Türkçe'nin kapalı sınıf ilgeçlerine, bağlaçlarına ve
söylem parçacıklarına dayanır (örn.
ile,ancak,fakat,çünkü,ki,ise).
Sorun giderme¶
ModuleNotFoundError: No module named 'spacy_stanza'— şunu çalıştırın:uv pip install 'bitig[turkish]'.FileNotFoundError: ... stanza_resources/tr/default.zip— şunu çalıştırın:python -c "import stanza; stanza.download('tr')". Model yaklaşık 600 MB'tır.- MPS'de çok yavaş ilk aktarım. Stanza'nın Türkçe modeli henüz Apple Silicon MPS'i desteklememektedir. İlk çalıştırmada CPU ayrıştırma hızları beklenir; sonraki çalıştırmalar önbellek isabetleridir.